Working on a remote HPC system
Overview
Teaching: 25 min
Exercises: 10 minQuestions
What is an HPC system?
How does an HPC system work?
How do I log on to a remote HPC system?
Objectives
Connect to a remote HPC system.
Understand the general HPC system architecture.
What is an HPC system?
The words “cloud”, “cluster”, and “high-performance computing” are used a lot in different contexts and with varying degrees of correctness. So what do they mean exactly? And more importantly, how do we use them for our work?
The cloud is a generic term commonly used to refer to remote computing resources of any kind – that is, any computers that you use but are not right in front of you. Cloud can refer to machines serving websites, providing shared storage, providing webservices (such as e-mail or social media platforms), as well as more traditional “compute” resources. An HPC system on the other hand, is a term used to describe a network of computers. The computers in a cluster typically share a common purpose, and are used to accomplish tasks that might otherwise be too big for any one computer.
Logging in
Go ahead and log in to the cluster: ARCHER at EPCC, The University of Edinburgh.
user@laptop:~$ ssh -XY yourUsername@login.archer.ac.uk
Remember to replace yourUsername with the username supplied by the instructors. You will be asked for
your password. But watch out, the characters you type are not displayed on the screen.
You are logging in using a program known as the secure shell or ssh.
This establishes a temporary encrypted connection between your laptop and login.archer.ac.uk.
The word before the @ symbol, e.g. yourUsername here, is the user account name for which you have access
permissions on the cluster.
The options -XY ensure that any Unix graphical output from ARCHER
(e.g. if you run a GUI, look at an image or plot a graph) are sent
back to your own laptop. You need to specify these options explicitly,
except if you are using MobaXterm when (like most things) it is set up
automatically.
Where do I get this
sshfrom ?On Linux and/or macOS, the
sshcommand line utility is almost always pre-installed. Open a terminal and typessh --helpto check if that is the case.At the time of writing, using openssh on Windows still requires some manual setup. There are a number of alternatives to this (e.g. putty, bitvise SSH, mRemoteNG) but the simplest to use is probably MobaXterm. As well as enabling command-line access via a terminal, MobaXterm also includes a drag-and-drop file transfer GUI and integrated Unix graphics.
Download MobaXterm, install it and open the GUI. The GUI asks for your user name and the destination address or IP of the computer you want to connect to. Once provided, you will be queried for your password just like in the example above.
Where are we?
Very often, many users are tempted to think of a high-performance computing installation as one
giant, magical machine. Sometimes, people will assume that the computer they’ve logged onto is the
entire computing cluster. So what’s really happening? What computer have we logged on to? The name
of the current computer we are logged onto can be checked with the hostname command. (You may also
notice that the current hostname is also part of our prompt!)
yourUsername@eslogin001:~> hostname
eslogin001
You may see a slightly different name from the one above, e.g. there might be a different numerical suffix. This is because your ssh connection may be directed to a range of different computers to balance the load with many interactive users on large clusters.
Nodes
Individual computers that compose a cluster are typically called nodes (although you will also hear people call them servers, computers and machines). On a cluster, there are different types of nodes for different types of tasks. The node where you are right now is called the head node, login node or submit node. A login node serves as an access point to the cluster. As a gateway, it is well suited for uploading and downloading files, setting up software, and running quick tests. It should never be used for doing actual work.
The real work on a cluster gets done by the worker (or compute) nodes. Worker nodes come in many shapes and sizes, but generally are dedicated to long or hard tasks that require a lot of computational resources.
All interaction with the worker nodes is handled by a specialized piece of software called a scheduler (the scheduler used in this lesson is called ). We’ll learn more about how to use the scheduler to submit jobs next, but for now, it can also tell us more information about the worker nodes.
For example, we can view all of the worker nodes with the pbsnodes -a command.
yourUsername@eslogin001:~> pbsnodes -a
mom3
Mom = nid01921
ntype = PBS
state = free
pcpus = 16
resources_available.arch = linux
resources_available.host = nid01921
resources_available.mem = 32991240kb
resources_available.ncpus = 16
resources_available.PBScrayhost = archer
resources_available.ppn = False
resources_available.vnode = mom3
resources_available.vntype = cray_login
resources_assigned.accelerator_memory = 0kb
resources_assigned.hbmem = 0kb
resources_assigned.mem = 0kb
resources_assigned.naccelerators = 0
resources_assigned.ncpus = 0
resources_assigned.netwins = 0
resources_assigned.nppus = 0
resources_assigned.vmem = 0kb
resv_enable = True
sharing = default_shared
license = l
...
There are also specialized machines used for managing disk storage, user authentication, and other infrastructure-related tasks. Although we do not typically logon to or interact with these machines directly, they enable a number of key features like ensuring our user account and files are available throughout the HPC system.
Shared file systems
This is an important point to remember: files saved on one node (computer) are often available everywhere on the cluster!
What’s in a node?
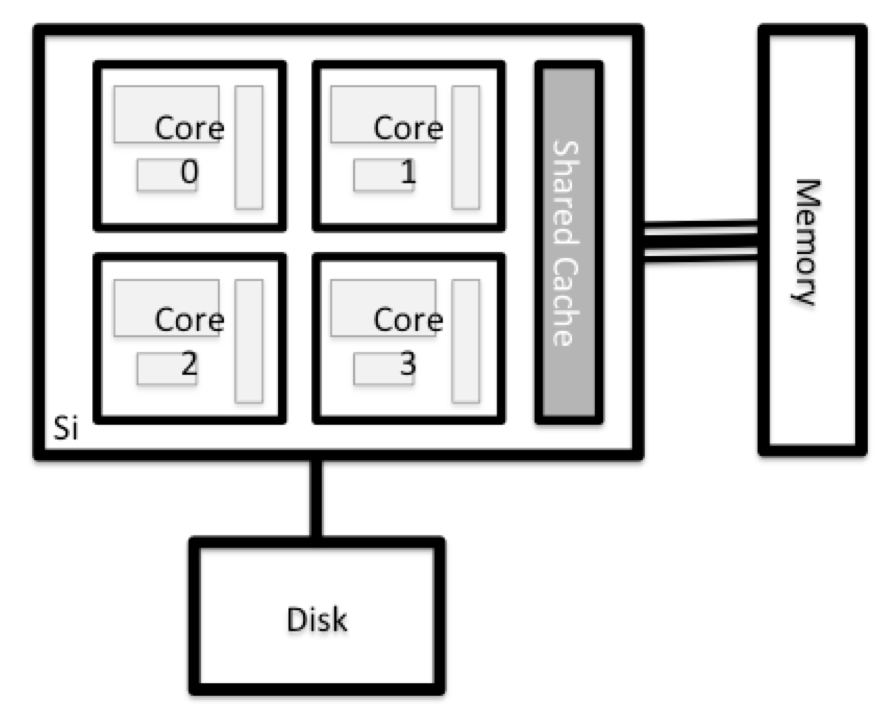
All of a HPC system’s nodes have the same components as your own laptop or desktop: CPUs (sometimes also called processors or cores), memory (or RAM), and disk space. CPUs are a computer’s tool for actually running programs and calculations. Information about a current task is stored in the computer’s memory. Disk refers to all storage that can be accessed like a file system. This is generally storage that can hold data permanently, i.e. data is still there even if the computer has been restarted.
On smaller systems there may be a separate physical disk on each node, just like the hard drive on your own laptop; large systems tend to have diskless nodes. However, on all systems the nodes will have access to a shared central disk storage system.
Explore Your Computer
Try to find out the number of CPUs and amount of memory available on your personal computer.
This can be surprisinglt challenging due to modern innovations such as multicore CPUs and hyper-threading. Your operating system may not be telling the whole truth!
Explore The Head Node
Now we’ll compare the size of your computer with the size of the head node: To see the number of processors, run:
yourUsername@eslogin001:~> nproc --allHow about memory? Try running:
yourUsername@eslogin001:~> free -m
Getting more information
You can get more detailed information on both the processors and memory by using different commands.
For more information on processors use
lscpuyourUsername@eslogin001:~> lscpuFor more information on memory you can look in the
/proc/meminfofile:yourUsername@eslogin001:~> cat /proc/meminfo
Explore a Worker Node
Finally, let’s look at the resources available on the worker nodes where your jobs will actually run. Try running this command to see the name, CPUs and memory available on the worker nodes (the instructors will give you the ID of the compute node to use):
yourUsername@eslogin001:~> pbsnodes archer_4917
Compare Your Computer, the Head Node and the Worker Node
Compare your laptop’s number of processors and memory with the numbers you see on the cluster head node and worker node. Discuss the differences with your neighbor. What implications do you think the differences might have on running your research work on the different systems and nodes?
Units and Language
A computer’s memory and disk are measured in units called Bytes (one Byte is 8 bits). As today’s files and memory have grown to be large given historic standards, volumes are noted using the SI prefixes. So 1000 Bytes is a Kilobyte (kB), 1000 Kilobytes is a Megabyte, 1000 Megabytes is a Gigabyte etc.
History and common language have however mixed this notation with a different meaning. When people say “Kilobyte”, they oftenmean 1024 Bytes instead. In that spirit, a Megabyte usually means 1024 Kilobytes. To address this ambiguity, the International System of Quantities standardizes the binary prefixes (with base of 1024) by the prefixes kibi, mibi, gibi, etc. For more details, see here
This confusion is due to a numerical coincidence. Computers count in binary (base 2), so for a computer it is natural that memory sizes should increase by factors of 2, i.e.
2^1= 2 bytes,2^2= 4 bytes,2^3= 8 bytes, … Rather remarkably,2^10= 1024 is very close to what us 10-fingered humans consider to be a nice round number of10^3= 1000.Computing would seem a lot simpler if evolution had given us all 3 fingers and a thumb …
Differences Between Nodes
Many HPC clusters have a variety of nodes optimized for particular workloads. Some nodes may have larger amount of memory, or specialized resources such as Graphical Processing Units (GPUs).
With all of this in mind, we will now cover how to talk to the cluster’s scheduler, and use it to start running our scripts and programs!
Key Points
An HPC system is a set of networked machines.
HPC systems typically provides login nodes and a set of worker nodes.
The resources found on independent (worker) nodes can vary in volume and type (amount of RAM, processor architecture, availability of network mounted file systems, etc.).
Files saved on one node are available on all nodes.