Overview of the Cirrus system
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What hardware and software is available on Cirrus?
How does the hardware fit together?
Objectives
Gain an overview of the technology available on the Cirrus service.
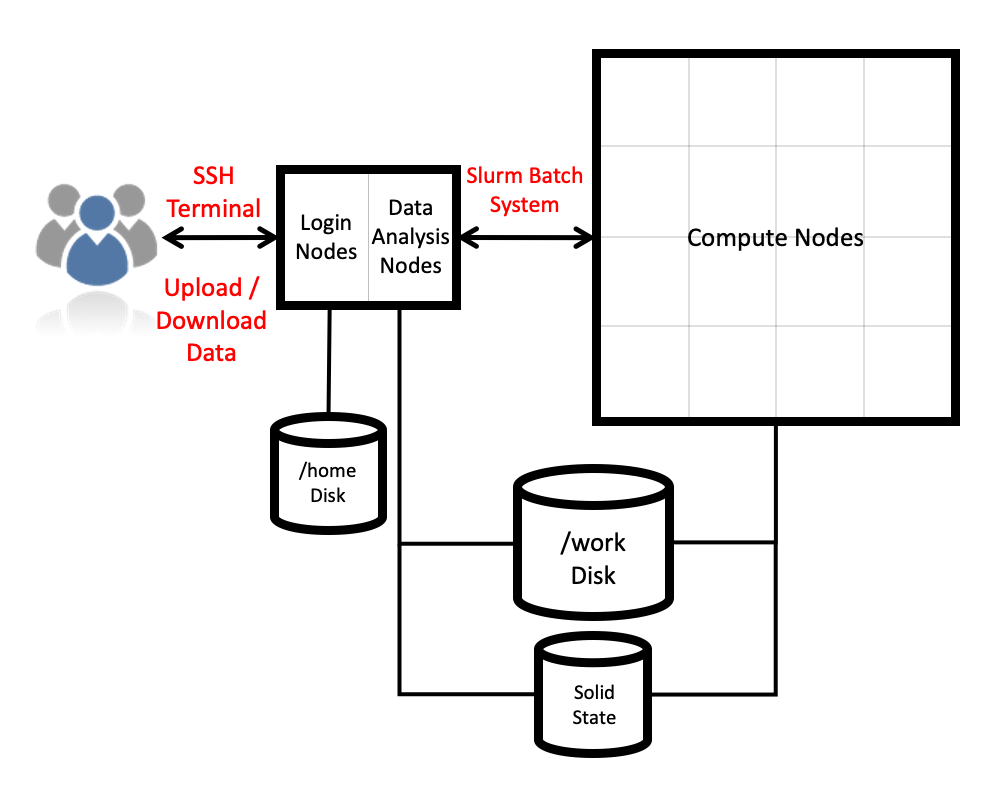
Architecture
The Cirrus HPE SGI ICE XA system consists of a number of different node types. The ones visible to users are:
- Login nodes
- CPU compute nodes
- GPU compute nodes
The CPU compute nodes each contain two 2.1 GHz, 18-core Intel Xeon E5-2695 (Broadwell) series processors. The GPU compute nodes each contain two 2.5 GHz, 20-core Intel Xeon Gold 6148 (Cascade Lake) series processors and four NVIDIA Tesla V100-SXM2-16GB (Volta) GPU accelerators connected to the host processors and each other via PCIe.
Compute nodes
There are 280 CPU compute nodes and 36 GPU compute nodes in total, giving 10,080 CPU compute cores and 144 GPUs on the full Cirrus system. The CPU compute nodes have 256 GiB memory per node, and the GPU compute nodes have 384 GiB per node. All of the compute nodes are linked together using the high-performance Infiniband fabric interconnect.
Access to the compute nodes is controlled by the Slurm scheduling system which supports both batch jobs and interactive jobs.
Compute node summary:
| Cirrus CPU nodes | Cirrus GPU nodes | |
|---|---|---|
| Processors | 2x Intel Xeon E5-2695 (Broadwell), 2.1 GHz, 18-core | 2x Intel Xeon Gold 6148 (Cascade Lake), 2.5 GHz, 20-core |
| Cores per node | 36 | 40 |
| NUMA | 2 NUMA regions per node, 18 cores per NUMA region | 2 NUMA regions per node, 20 cores per NUMA region |
| Memory Capacity | 256 GiB | 384 GiB |
| GPUs per node | 4x NVIDIA Tesla V100-SXM2-16GB (Volta) | |
| Interconnect Bandwidth | 54.5 GB/s | 54.5 GB/s |
Storage
There are three different storage systems available on the current Cirrus service:
- Home file systems
- Work file systems
- Solid state storage
Home
The home file systems are available on the login nodes only, and are designed for the storage of critical source code and data for Cirrus users. They are backed-up regularly offsite for disaster recovery purposes and support recovery of data that has been deleted by accident. There is a total of 1.5 PB usable space available on the home file systems.
All users have their own directory on the home file systems at:
/home/<projectID>/<subprojectID>/<userID>
For example, if your username is auser and you are in the project ic084 then your home
directory will be at:
/home/ic084/ic084/auser
Home file system and Home directory
A potential source of confusion is the distinction between the home file system which is the storage system on Cirrus used for critical data and your home directory which is a Linux concept of the directory that you are placed into when you first login, that is stored in the
$HOMEenvironment variable and that can be accessed with thecd ~command.
You can view your home file system quota and use through SAFE. Use the Login account menu to select the account you want to see the information for. The account summary page will contain information on your home file system use and any quotas (user or project) that apply to that account. (SAFE home file system use data is updated daily so the information may not quite match the state of the system if a large change has happened recently. Quotas will be completely up to date as they are controlled by SAFE.)
Work
The work file systems, which are available on the login, data analysis and compute nodes, are designed for high performance parallel access and are the primary location that jobs running on the compute nodes will read data from and write data to. They are based on the Lustre parallel file system technology. The work file systems are not backed up in any way. There is a total of 24 PB usable space available on the work file systems.
All users have their own directory on the work file systems at:
/work/<projectID>/<subprojectID>/<userID>
For example, if your username is auser and you are in the project ic084 then your main work
directory will be at:
/work/ic084/ic084/auser
Jobs can’t see your data?
If your jobs are having trouble accessing your data make sure you have placed it on the work file systems rather than the home file systems. Remember, the home file systems are not visible from the compute nodes.
You can view your work file system use and quota through SAFE in the same way as described for the home file system above.
Sharing data with other users
Both the home and work file systems have special directories that allow you to share data with other users. There are directories that allow you to share data only with other users in the same project and directories that allow you to share data with users in other projects.
To share data with users in the same project you use the /work/ic084/ic084/shared directory
(remember to replace ic084 with your project ID) and make sure the permissions on the
directory are correctly set to allow sharing in the project:
auser@cirrus-login2:~> mkdir /work/ic084/ic084/shared/interesting-data
auser@cirrus-login2:~> cp -r modelling-output /work/ic084/ic084/shared/interesting-data/
auser@cirrus-login2:~> chmod -R g+rX,o-rwx /work/ic084/ic084/shared/interesting-data
auser@cirrus-login2:~> ls -l /work/ic084/ic084/shared
total 150372
...snip...
drwxr-s--- 2 auser ic084 4096 Jul 20 12:09 interesting-data
..snip...
To share data with users in other projects, you use the /work/ic084/shared directory
(remember to replace ic084 with your project ID) and make sure the permissions on the
directory are correctly set to allow sharing with all other users:
auser@cirrus-login2:~> mkdir /work/ic084/shared/more-interesting-data
auser@cirrus-login2:~> cp -r more-modelling-output /work/ic084/shared/more-interesting-data/
auser@cirrus-login2:~> chmod -R go+rX /work/ic084/shared/more-interesting-data
auser@cirrus-login2:~> ls -l /work/ic084/shared
total 150372
...snip...
drwxr-sr-x 2 auser ic084 4096 Jul 20 12:09 more-interesting-data
..snip...
Remember, equivalent sharing directories exist on the home file system that you can use in exactly the same way.
Solid state storage
The Cirrus login and compute nodes have access to a shared, high-performance, solid state storage system (also known as RPOOL). This storage system is network mounted and shared across the login nodes and GPU compute nodes in a similar way to the normal, spinning-disk Lustre file system but has different performance characteristics.
The solid state storage has a maximum usable capacity of 256 TB which is shared between all users.
Machine learning and solid state storage
Solid state storage usually has significantly better I/O performance. This usually makes it the best solution for running machine learning training (which requires a lot of reading from large files).
For this course, we recommend running all work from this filesystem!
For this course, we have created a directory on the solid state storage. You can access it by running:
auser@cirrus-login2:~> cd /scratch/space1/ic084
If this is your first time in this directory, you will need to create a directory to work from. You can do this by running:
auser@cirrus-login2:~> mkdir $USER
auser@cirrus-login2:~> cd $USER
You can transfer data locally to this directory by running:
auser@cirrus-login2:~> cp -r /path/to/data-dir /scratch/space1/ic084/$USER/
For remote transfers to this directory, you will need to use rscync or
scp – you can use the following command as an example (making sure to
replace <username> with your Cirrus username):
auser@local-machine:~> scp -r data-dir <username>@login.cirrus.ac.uk:/scratch/space1/ic084/$USER/
System software
The Cirrus system runs the * HPE Cray Linux Environment* which is based on SUSE Enterprise Linux. The service officially supports the bash shell for interactive access, shell scripting and job submission scripts. The scheduling software is Slurm.
As well as the hardware and system software, HPE supply the HPE Cray Programming Environment which contains:
| Compilers | GNU, Intel, NVIDIA |
| Parallel libraries | MPI, OpenMP, SYCL, CUDA, OpenACC |
| Scientific and numerical libraries | BLAS, LAPACK, BLACS, ScaLAPACK, FFTW3, HDF5, NetCDF |
In addition to this, the EPCC Cirrus CSE service have installed a wide range of modelling and simulation software, additional scientific and numeric libraries, data analysis tools and other useful software. Some examples of the software installed are:
| Research area | Software |
|---|---|
| Materials and molecular modelling | CASTEP, CP2K, LAMMPS, Quantum Espresso, VASP |
| Engineering | OpenFOAM |
| Biomolecular modelling | GROMACS, NAMD |
| Scientific libraries | Intel MKL, HDF5 |
| Software tools | Linaro Forge, Scalasca, Intel VTune |
More information on the software available on Cirrus can be found in the Cirrus Documentation.
Cirrus also supports the use of Singularity containers for single-node and multi-node jobs.
Key Points
Cirrus consists of login nodes, compute nodes, storage systems and interconnect.
There is a wide range of software available on Cirrus.
The system is based on standard Linux with command line access.