Working on a remote HPC system
Last updated on 2025-01-14 | Edit this page
Estimated time: 35 minutes
Overview
Questions
- “What is an HPC system?”
- “How does an HPC system work?”
- “How do I log on to a remote HPC system?”
Objectives
- “Connect to a remote HPC system.”
- “Understand the general HPC system architecture.”
What Is an HPC System?
The words “cloud”, “cluster”, and the phrase “high-performance computing” or “HPC” are used a lot in different contexts and with various related meanings. So what do they mean? And more importantly, how do we use them in our work?
The cloud is a generic term commonly used to refer to computing resources that are a) provisioned to users on demand or as needed and b) represent real or virtual resources that may be located anywhere on Earth. For example, a large company with computing resources in Brazil, Zimbabwe and Japan may manage those resources as its own internal cloud and that same company may also utilize commercial cloud resources provided by Amazon or Google. Cloud resources may refer to machines performing relatively simple tasks such as serving websites, providing shared storage, providing web services (such as e-mail or social media platforms), as well as more traditional compute intensive tasks such as running a simulation.
The term HPC system, on the other hand, describes a stand-alone resource for computationally intensive workloads. They are typically comprised of a multitude of integrated processing and storage elements, designed to handle high volumes of data and/or large numbers of floating-point operations (FLOPS) with the highest possible performance. For example, all of the machines on the Top-500 list are HPC systems. To support these constraints, an HPC resource must exist in a specific, fixed location: networking cables can only stretch so far, and electrical and optical signals can travel only so fast.
The word “cluster” is often used for small to moderate scale HPC resources less impressive than the Top-500. Clusters are often maintained in computing centers that support several such systems, all sharing common networking and storage to support common compute intensive tasks.
Logging In
The first step in using a cluster is to establish a connection from our laptop to the cluster. When we are sitting at a computer (or standing, or holding it in our hands or on our wrists), we have come to expect a visual display with icons, widgets, and perhaps some windows or applications: a graphical user interface, or GUI. Since computer clusters are remote resources that we connect to over often slow or laggy interfaces (WiFi and VPNs especially), it is more practical to use a command-line interface, or CLI, in which commands and results are transmitted via text, only. Anything other than text (images, for example) must be written to disk and opened with a separate program.
If you have ever opened the Windows Command Prompt or macOS Terminal, you have seen a CLI. If you have already taken The Carpentries’ courses on the UNIX Shell or Version Control, you have used the CLI on your local machine somewhat extensively. The only leap to be made here is to open a CLI on a remote machine, while taking some precautions so that other folks on the network can’t see (or change) the commands you’re running or the results the remote machine sends back. We will use the Secure SHell protocol (or SSH) to open an encrypted network connection between two machines, allowing you to send & receive text and data without having to worry about prying eyes.

Make sure you have a SSH client installed on your laptop. Refer to
the setup section for more details. SSH clients
are usually command-line tools, where you provide the remote machine
address as the only required argument. If your username on the remote
system differs from what you use locally, you must provide that as well.
If your SSH client has a graphical front-end, such as PuTTY or
MobaXterm, you will set these arguments before clicking “connect.” From
the terminal, you’ll write something like
ssh userName@hostname, where the “@” symbol is used to
separate the two parts of a single argument.
Go ahead and open your terminal or graphical SSH client, then log in to the cluster using your username and the remote computer you can reach from the outside world, EPCC, The University of Edinburgh.
Remember to replace userid with your username or the one
supplied by the instructors. You may be asked for your password. Watch
out: the characters you type after the password prompt are not displayed
on the screen. Normal output will resume once you press
Enter.
Where Are We?
Very often, many users are tempted to think of a high-performance
computing installation as one giant, magical machine. Sometimes, people
will assume that the computer they’ve logged onto is the entire
computing cluster. So what’s really happening? What computer have we
logged on to? The name of the current computer we are logged onto can be
checked with the hostname command. (You may also notice
that the current hostname is also part of our prompt!)
What’s in Your Home Directory?
The system administrators may have configured your home directory
with some helpful files, folders, and links (shortcuts) to space
reserved for you on other filesystems. Take a look around and see what
you can find. Hint: The shell commands pwd and
ls may come in handy. Home directory contents vary from
user to user. Please discuss any differences you spot with your
neighbors.
The deepest layer should differ: userid is uniquely
yours. Are there differences in the path at higher levels?
If both of you have empty directories, they will look identical. If you or your neighbor has used the system before, there may be differences. What are you working on?
Use pwd to print the
working directory path:
You can run ls to list
the directory contents, though it’s possible nothing will show up (if no
files have been provided). To be sure, use the -a flag to
show hidden files, too.
At a minimum, this will show the current directory as .,
and the parent directory as ...
Nodes
Individual computers that compose a cluster are typically called nodes (although you will also hear people call them servers, computers and machines). On a cluster, there are different types of nodes for different types of tasks. The node where you are right now is called the head node, login node, landing pad, or submit node. A login node serves as an access point to the cluster.
As a gateway, it is well suited for uploading and downloading files, setting up software, and running quick tests. Generally speaking, the login node should not be used for time-consuming or resource-intensive tasks. You should be alert to this, and check with your site’s operators or documentation for details of what is and isn’t allowed. In these lessons, we will avoid running jobs on the head node.
Dedicated Transfer Nodes
If you want to transfer larger amounts of data to or from the cluster, some systems offer dedicated nodes for data transfers only. The motivation for this lies in the fact that larger data transfers should not obstruct operation of the login node for anybody else. Check with your cluster’s documentation or its support team if such a transfer node is available. As a rule of thumb, consider all transfers of a volume larger than 500 MB to 1 GB as large. But these numbers change, e.g., depending on the network connection of yourself and of your cluster or other factors.
The real work on a cluster gets done by the worker (or compute) nodes. Worker nodes come in many shapes and sizes, but generally are dedicated to long or hard tasks that require a lot of computational resources.
All interaction with the worker nodes is handled by a specialized piece of software called a scheduler (the scheduler used in this lesson is called Slurm). We’ll learn more about how to use the scheduler to submit jobs next, but for now, it can also tell us more information about the worker nodes.
For example, we can view all of the worker nodes by running the
command sinfo.
OUTPUT
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
standard up 1-00:00:00 27 drain* nid[001029,001050,001149,001363,001366,001391,001552,001568,001620,001642,001669,001672-001675,001688,001690-001691,001747,001751,001783,001793,001812,001832-001835]
standard up 1-00:00:00 5 down* nid[001024,001026,001064,001239,001898]
standard up 1-00:00:00 8 drain nid[001002,001028,001030-001031,001360-001362,001745]
standard up 1-00:00:00 945 alloc nid[001000-001001,001003-001023,001025,001027,001032-001037,001040-001049,001051-001063,001065-001108,001110-001145,001147,001150-001238,001240-001264,001266-001271,001274-001334,001337-001359,001364-001365,001367-001390,001392-001551,001553-001567,001569-001619,001621-001637,001639-001641,001643-001668,001670-001671,001676,001679-001687,001692-001734,001736-001744,001746,001748-001750,001752-001782,001784-001792,001794-001811,001813-001824,001826-001831,001836-001890,001892-001897,001899-001918,001920,001923-001934,001936-001945,001947-001965,001967-001981,001984-001991,002006-002023]
standard up 1-00:00:00 37 resv nid[001038-001039,001109,001146,001148,001265,001272-001273,001335-001336,001638,001677-001678,001735,001891,001919,001921-001922,001935,001946,001966,001982-001983,001992-002005] There are also specialized machines used for managing disk storage, user authentication, and other infrastructure-related tasks. Although we do not typically logon to or interact with these machines directly, they enable a number of key features like ensuring our user account and files are available throughout the HPC system.
What's in a Node?
All of the nodes in an HPC system have the same components as your own laptop or desktop: CPUs (sometimes also called processors or cores), memory (or RAM), and disk space. CPUs are a computer’s tool for actually running programs and calculations. Information about a current task is stored in the computer’s memory. Disk refers to all storage that can be accessed like a file system. This is generally storage that can hold data permanently, i.e. data is still there even if the computer has been restarted. While this storage can be local (a hard drive installed inside of it), it is more common for nodes to connect to a shared, remote fileserver or cluster of servers.
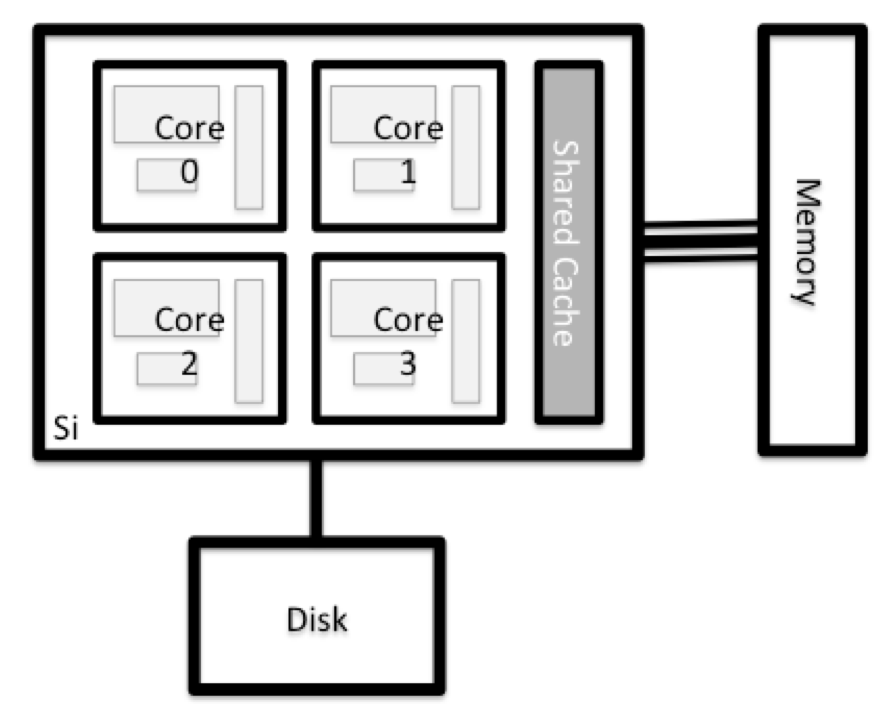
There are several ways to do this. Most operating systems have a graphical system monitor, like the Windows Task Manager. More detailed information can sometimes be found on the command line. For example, some of the commands used on a Linux system are:
Run system utilities
Read from /proc
Run system monitor
Explore the login node
Now compare the resources of your computer with those of the head node.
BASH
[user@laptop ~]$ ssh userid@login.archer2.ac.uk
userid@ln03:~> nproc --all
userid@ln03:~> free -mYou can get more information about the processors using
lscpu, and a lot of detail about the memory by reading the
file /proc/meminfo:
You can also explore the available filesystems using df
to show disk free space. The
-h flag renders the sizes in a human-friendly format, i.e.,
GB instead of B. The type flag -T shows
what kind of filesystem each resource is.
Discussion
The local filesystems (ext, tmp, xfs, zfs) will depend on whether you’re on the same login node (or compute node, later on). Networked filesystems (beegfs, cifs, gpfs, nfs, pvfs) will be similar — but may include userid, depending on how it is mounted.
Compare Your Computer, the login node and the compute node
Compare your laptop’s number of processors and memory with the numbers you see on the cluster head node and worker node. Discuss the differences with your neighbor.
What implications do you think the differences might have on running your research work on the different systems and nodes?
Differences Between Nodes
Many HPC clusters have a variety of nodes optimized for particular workloads. Some nodes may have larger amount of memory, or specialized resources such as Graphical Processing Units (GPUs).
With all of this in mind, we will now cover how to talk to the cluster’s scheduler, and use it to start running our scripts and programs!
Key Points
- “An HPC system is a set of networked machines.”
- “HPC systems typically provide login nodes and a set of worker nodes.”
- “The resources found on independent (worker) nodes can vary in volume and type (amount of RAM, processor architecture, availability of network mounted filesystems, etc.).”
- “Files saved on one node are available on all nodes.”