Overview of the ARCHER2 system
Overview
Teaching: 30 min
Exercises: 15 minQuestions
What hardware and software is available on ARCHER2?
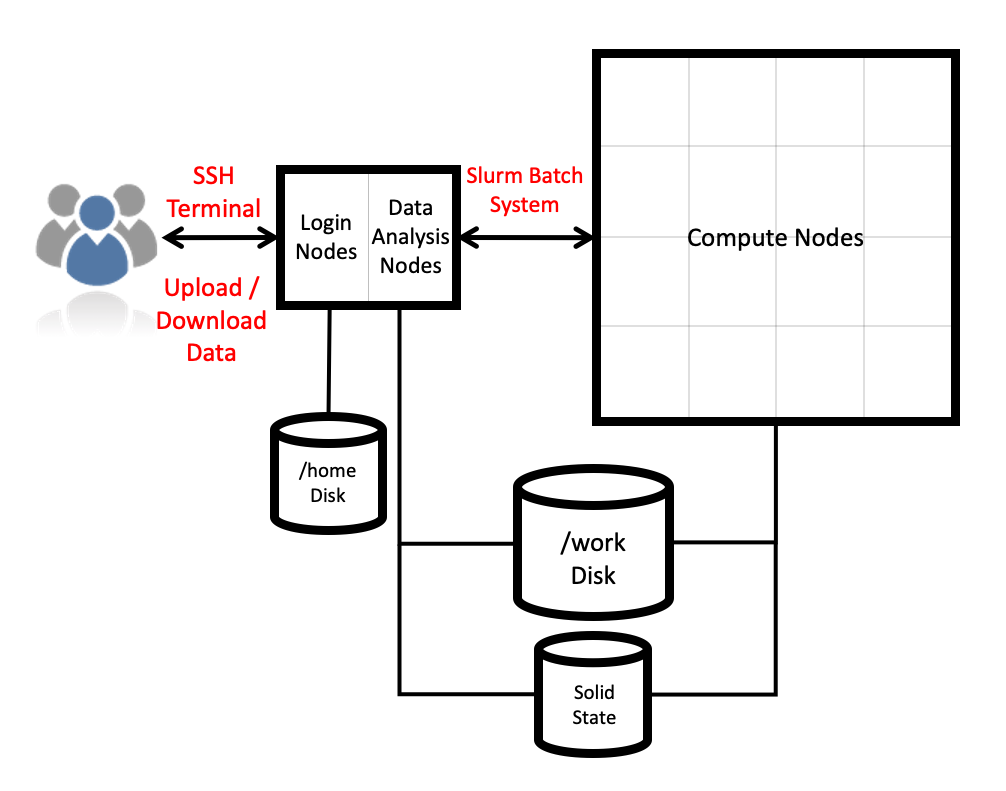
How does the hardware fit together?
Objectives
Gain an overview of the technology available on the ARCHER2 service.
Architecture
The ARCHER2 HPE Cray EX system consists of a number of different node types. The ones visible to users are:
- Login nodes
- Compute nodes
- Data analysis (pre-/post- processing) nodes
All of the node types have the same processors: AMD EPYC Zen2 7742, 2.25GHz, 64-cores. All nodes are dual socket nodes so there are 128 cores per node.
Compute nodes
There are 5,860 compute nodes in total giving 748,544 compute cores on ARCHER2. There are 5,276 standard compute nodes with 256 GiB memory per node and 584 high memory compute nodes with 512 GiB of memory per node. All of the compute nodes are linked together using the high-performance Cray Slingshot interconnect.
Access to the compute nodes is controlled by the Slurm scheduling system which supports both batch jobs and interactive jobs.
Compute node summary (with comparison to ARCHER):
| ARCHER2 | ARCHER | |
|---|---|---|
| Processors | 2x AMD EPYC Zen2 (Rome) 7742, 2.25 GHz, 64-core | 2x Intel E5-2697 v2, 2.7 GHz, 12-core |
| Cores per node | 128 | 24 |
| NUMA | 8 NUMA regions per node, 16 cores per NUMA region | 2 NUMA regions per node, 12 cores per NUMA region |
| Memory Capacity | 256/512 GB DDR 3200, 8 memory channels | 64/128 GB DDR 1666, 4 memory channels |
| Memory Bandwidth | >380 GB/s per node | >119 GB/s per node |
| Interconnect Bandwidth | 25 GB/s per node bi-directional | 15 GB/s per node bi-directional |
Storage
There are four different storage systems available on ARCHER2:
- Home
- Work
- Solid State
- RDFaaS
Home
The home file systems are available on the login nodes only and are designed for the storage of critical source code and data for ARCHER2 users. They are backed-up regularly offsite for disaster recovery purposes - restoration of accidentally deleted files is not supported. There is a total of 1 PB usable space available on the home file systems.
All users have their own directory on the home file systems at:
/home/<projectID>/<subprojectID>/<userID>
For example, if your username is auser and you are in the project ta043 then your home
directory will be at:
/home/ta043/ta043/auser
Home file system and Home directory
A potential source of confusion is the distinction between the home file system which is the storage system on ARCHER2 used for critical data and your home directory which is a Linux concept of the directory that you are placed into when you first login, that is stored in the
$HOMEenvironment variable and that can be accessed with thecd ~command.
You can view your home file system quota and use through SAFE. Use the Login account menu to select the account you want to see the information for. The account summary page will contain information on your home file system use and any quotas (user or project) that apply to that account. (SAFE home file system use data is updated daily so the information may not quite match the state of the system if a large change has happened recently. Quotas will be completely up to date as they are controlled by SAFE.)
Subprojects?
Some large projects may choose to split their resources into multiple subprojects. These subprojects will have identifiers prepended with the main project ID. For example, the
rsesubgroup of theta043project would have the IDta043-rse. If the main project has allocated storage quotas to the subproject the directories for this storage will be found at, for example:/home/ta043/ta043-rse/auserYour Linux home directory will generally not be changed when you are made a member of a subproject so you must change directories manually (or change the ownership of files) to make use of this different storage quota allocation.
Work
The work file systems, which are available on the login, compute and data analysis nodes, are designed for high performance parallel access and are the primary location that jobs running on the compute nodes will read data from and write data to. They are based on the Lustre parallel file system technology. The work file systems are not backed up in any way. There is a total of 14.5 PB usable space available on the work file systems.
All users have their own directory on the work file systems at:
/work/<projectID>/<subprojectID>/<userID>
For example, if your username is auser and you are in the project ta043 then your main home
directory will be at:
/work/ta043/ta043/auser
Jobs can’t see your data?
If your jobs are having trouble accessing your data make sure you have placed it on Work rather than Home. Remember, the home file systems are not visible from the compute nodes.
You can view your work file system use and quota through SAFE in the same way as described
for the home file system above. If you want more up to date information, you can query
the quotas and use directly on ARCHER2 itself using the lfs quota command. For example,
to query your project quota on the work file system you could use:
lfs quota -hg ta043 /work
Disk quotas for group ta043 (gid 1001):
Filesystem used quota limit grace files quota limit grace
/work 17.24T 0k 21.95T - 6275076 0 10000000 -
(Remember to replace ta043 with your project code.) The used column shows how much space
the whole project is using and the limit column shows how much quota is available for the
project. You can show your own user’s use and quota with:
lfs quota -hu auser /work
Disk quotas for user auser (uid 5496):
Filesystem used quota limit grace files quota limit grace
/work 8.526T 0k 0k - 764227 0 0 -
A limit of 0k here shows that no user quota is in place (but you are still bound by an overall project quota in this case.)
Solid State
The solid state storage system is available on the compute nodes and is designed for the highest read and write performance to improve performance of workloads that are I/O bound in some way. Access to solid state storage resources is controlled through the Slurm scheduling system. The solid state storage is not backed up in any way. There is a total of 1.1 PB usable space available on the solid state storage system.
Data on the solid state storage is transient so all data you require before a job starts or after a job finishes must be staged on to or off of the solid state storage. We discuss how this works in the Scheduler episode later.
RDFaaS
If you had data on the /epsrc or /general file systems on the RDF, you will be able to access
this on ARCHER2 via the RDFaaS (RDF as a Service). The directory structure is the same as on the
home and work file systems, so an RDF user named auser in the e05 project would find their data
on the RDFaaS at
/epsrc/e05/e05/auser
Data on the RDFaaS is only visible on the login nodes, so should be copied to work before use in jobs.
Sharing data with other users
Both the home and work file systems have special directories that allow you to share data with other users. There are directories that allow you to share data only with other users in the same project and directories that allow you to share data with users in other projects.
To share data with users in the same project you use the /work/ta043/ta043/shared directory
(remember to replace ta043 with your project ID) and make sure the permissions on the
directory are correctly set to allow sharing in the project:
auser@ln01:~> mkdir /work/ta043/ta043/shared/interesting-data
auser@ln01:~> cp -r modelling-output /work/ta043/ta043/shared/interesting-data/
auser@ln01:~> chmod -R g+rX,o-rwx /work/ta043/ta043/shared/interesting-data
auser@ln01:~> ls -l /work/ta043/ta043/shared
total 150372
...snip...
drwxr-s--- 2 auser z01 4096 Jul 20 12:09 interesting-data
..snip...
To share data with users in other projects, you use the /work/ta043/shared directory
(remember to replace ta043 with your project ID) and make sure the permissions on the
directory are correctly set to allow sharing with all other users:
auser@ln01:~> mkdir /work/ta043/shared/more-interesting-data
auser@ln01:~> cp -r more-modelling-output /work/ta043/shared/more-interesting-data/
auser@ln01:~> chmod -R go+rX /work/ta043/shared/more-interesting-data
auser@ln01:~> ls -l /work/ta043/ta043/shared
total 150372
...snip...
drwxr-sr-x 2 auser z01 4096 Jul 20 12:09 more-interesting-data
...snip...
Remember, equivalent sharing directories exist on the home file system that you can use in exactly the same way.
System software
The ARCHER2 system runs the Cray Linux Environment which is based on SUSE Enterprise Linux. The service officially supports the bash shell for interactive access, shell scripting and job submission scripts. The scheduling software is Slurm.
As well as the hardware and system software, HPE Cray supply the Cray Programming Environment which contains:
| Compilers | GCC, Cray Compilers (CCE), AMD Compilers (AOCC) |
| Parallel libraries | Cray MPI (MPICH2-based), OpenSHMEM, Global Arrays |
| Scientific and numerical libraries | BLAS/LAPACK/BLACS/ScaLAPACK (Cray LibSci, AMD AOCL), FFTW3, HDF5, NetCDF |
| Debugging and profiling tools | gdb4hpc, valgrind4hpc, CrayPAT + others |
| Optimised Python 3 environment | numpy, scipy, mpi4py, dask |
| Optimised R environment | standard packages (including “parallel”) |
The largest differences from ARCHER are:
- Addition of optimised Python 3 and R environments
- Lack of Intel compilers and MKL libraries
- Lack of Arm Forge: DDT debugger and MAP profiler
On top of the Cray-provided software, the EPCC ARCHER2 CSE service have installed a wide range of modelling and simulation software, additional scientific and numeric libraries, data analysis tools and other useful software. Some examples of the software installed are:
| Research area | Software |
|---|---|
| Materials and molecular modelling | CASTEP, ChemShell, CP2K, Elk, LAMMPS, NWChem, ONETEP, Quantum Espresso, VASP |
| Engineering | Code_Saturne, FEniCS, OpenFOAM |
| Biomolecular modelling | GROMACS, NAMD |
| Earth system modelling | MITgcm, Met Office UM, Met Office LFRic, NEMO |
| Scientific libraries | ARPACK, Boost, Eigen, ELPA, GSL, HYPRE, METIS, MUMPS, ParaFEM, ParMETIS, PETSc, Scotch, SLEPC, SUNDIALS, Zoltan |
| Software tools | CDO, CGNS, NCL, NCO, Paraview, PLUMED, PyTorch, Tensorflow, VMD, VTST |
Licensed software
For licensed software installed on ARCHER2, users are expected to bring their own licences to the service with them. The ARCHER2 service does not provide software licences for use by users. Access to licensed software is available via three different mechnisms:
- Access control groups - for software that does not support a licence server
- Local licence server - for software that requires a licence server running on the ARCHER2 system
- Remote licence server - to allow software to call out to a publicly-accessible licence server
More information on the software available on ARCHER2 can be found in the ARCHER2 Documentation.
ARCHER2 also supports the use of Singularity containers for single-node and multi-node jobs.
What about your research?
Speak to your neighbour about your planned use of ARCHER2. Given what you now know about the system, what do you think the biggest opportunities are for your research in using ARCHER2? What do you think the largest challenges are going to be for you?
Write a few sentences in the course Etherpad describing the opportunities and challenges you discussed.
Key Points
ARCHER2 consists of high performance login nodes, compute nodes, storage systems and interconnect.
There is a wide range of software available on ARCHER2.
The system is based on standard Linux with command line access.